
Pequenos Modelos, Grande ROI: Por que Você Não Precisa do GPT-5 para Tudo

Sumário
- Pequenos Modelos, Grande ROI: Por que Você Não Precisa do GPT-5 para Tudo
- NPUs + Edge AI: A Revolução do Hardware
- Model Spotlight: SLMs que Entregam ROI
- Microsoft Phi-4 (Reasoning)
- Meta Llama-4 (Multimodal & MoE)
- Arquitetura Híbrida com Semantic Routing
- Métricas que acompanho em produção
- Privacidade e o "Air Gap" Lógico
- WebGPU: O Poder da IA no Navegador
- Quando usar WebGPU vs NPU
- KPIs e ROI que Tech Leads Monitoram
- Checklist para Adotar SLMs na Borda
- Conclusão: Inteligência como Commodity Distribuída
- Principais Aprendizados
- Fontes
Pequenos Modelos, Grande ROI: Por que Você Não Precisa do GPT-5 para Tudo
Em 2024 e 2025, a corrida da IA foi definida pelo tamanho. "Quem tem mais parâmetros?", "Qual modelo pontua mais alto no MMLU?". Mas agora, em 2026, a conversa mudou drasticamente. Não perguntamos mais "quão inteligente é o modelo", e sim "qual SLM entrega eficiência para esta tarefa específica?".
A era dos Small Language Models (SLMs) chegou com força total. A ideia de que "maior é melhor" colapsou sob o peso dos custos de inferência, da latência e da falta de controle de dados. Hoje, usar um modelo massivo como GPT-5 ou Claude Opus é como ligar um data center para resolver uma query SQL — funciona, mas é o oposto de Edge AI FinOps.
Neste post mostro por que arquitetos e tech leads migraram para arquiteturas híbridas e como rodar IA na borda se tornou a estratégia número um para reduzir custos, garantir privacidade e manter respostas em 50 ms.
Você vai ver:
- Como NPUs e WebGPU destravaram SLMs de 3-8B em dispositivos de consumo.
- Padrões de roteamento semântico que combinam SLMs e LLMs gigantes com ROI positivo.
- Métricas e checklists que uso para provar valor a CFOs e heads de produto.
NPUs + Edge AI: A Revolução do Hardware
Não é só o software que mudou. O hardware de 2026 finalmente alcançou as ambições da IA. Hoje, quase todo notebook e smartphone vem equipado com uma NPU (Neural Processing Unit) dedicada, criando um parque instalado perfeito para Edge AI.
Diferente das GPUs que devoram bateria, as NPUs são projetadas para rodar inferência com eficiência energética extrema. Isso significa que conseguimos executar modelos de 3 a 7 bilhões de parâmetros em background, o dia todo, sem drenar a bateria do usuário. Abre-se espaço para assistentes always-on que realmente conhecem o contexto local do usuário e respeitam o air gap lógico.
Vendors que merecem atenção: Apple (M4 + Neural Engine), Qualcomm X Elite, AMD Strix Point e NPUs discretas da Intel. Todos já expõem APIs para desenvolvedores integrarem SLMs em apps nativos.
Não é só o software que mudou. O hardware de 2026 finalmente alcançou as ambições da IA. Hoje, quase todo notebook e smartphone vem equipado com uma NPU (Neural Processing Unit) dedicada, criando um parque instalado perfeito para Edge AI.
Diferente das GPUs que devoram bateria, as NPUs são projetadas para rodar inferência com eficiência energética extrema. Isso significa que conseguimos executar modelos de 3 a 7 bilhões de parâmetros em background, o dia todo, sem drenar a bateria do usuário. Abre-se espaço para assistentes always-on que realmente conhecem o contexto local do usuário e respeitam o air gap lógico.
Vendors que merecem atenção: Apple (M4 + Neural Engine), Qualcomm X Elite, AMD Strix Point e NPUs discretas da Intel. Todos já expõem APIs para desenvolvedores integrarem SLMs em apps nativos.

Model Spotlight: SLMs que Entregam ROI
Dois modelos definiram este ano:
Microsoft Phi-4 (Reasoning)
A Microsoft provou que "livros didáticos são tudo o que você precisa". O Phi-4 não é apenas um modelo pequeno; é um especialista em raciocínio. Treinado com dados sintéticos de alta qualidade ("textbook quality"), ele supera modelos 10x maiores em tarefas de lógica, matemática e codificação. Para tarefas de agente que exigem planejamento estruturado, ele é o novo padrão-ouro e cabe em uma GPU de 8 GB.
Por que importa para tech leads: ele acelera code review automatizado local, reduzindo latência para menos de 40 ms e viabilizando auditorias offline.
Meta Llama-4 (Multimodal & MoE)
A Meta respondeu com o Llama-4, focado em arquitetura Mixture-of-Experts (MoE). Em vez de ativar todos os 8 bilhões de parâmetros para cada token, o modelo ativa apenas os "experts" necessários (cerca de 2B), mantendo a inteligência de um modelo denso com a velocidade de um modelo minúsculo. Além disso, sua capacidade multimodal nativa permite que ele "veja" e "ouça" diretamente no dispositivo.
Por que importa para produto: experiências multimodais nativas habilitam copilotos que entendem logs, áudio de atendimento e contexto visual sem enviar dados para a nuvem.
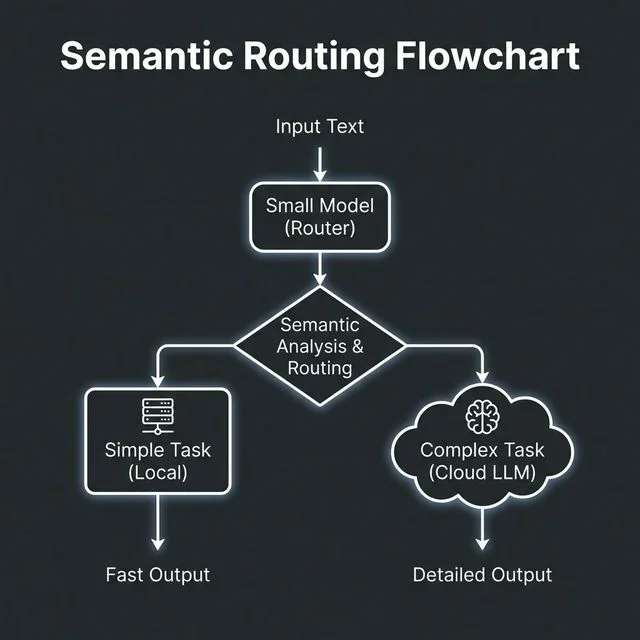
Arquitetura Híbrida com Semantic Routing
A solução não é abandonar os grandes modelos, mas usá-los estrategicamente. O padrão de design dominante em 2026 é a Arquitetura de Roteamento Semântico.
Funciona assim:
- O Porteiro (Gateway SLM): Uma requisição chega e é interceptada por um modelo local (SLM) rodando no device ou na borda da CDN.
- Triagem: Esse modelo classifica a complexidade. É uma formatação JSON? Um resumo de texto? O SLM resolve ali mesmo (Custo $0, Latência <50ms).
- Escalonamento: É um raciocínio criativo complexo? O SLM encaminha para o "Big Brain" na nuvem (GPT-5/Claude).
Essa abordagem reduz a conta de inferência em até 70% em grandes operações, mantendo a qualidade onde ela importa.
Métricas que acompanho em produção
- Hit ratio do roteador semântico: porcentagem de requisições resolvidas localmente (meta: 65%+).
- Latência P95 por tier: <50 ms no SLM, <350 ms no LLM premium.
- Custo por mil requisições (CPM): transformar FinOps em narrativa objetiva para CFOs.
Privacidade e o "Air Gap" Lógico
Além do custo, a privacidade é o grande impulsionador do Edge AI. Com regulamentações globais de dados cada vez mais rígidas, processar informações sensíveis localmente é um diferencial competitivo enorme.
Casos de Uso Real:
- Saúde: Um app que analisa sintomas ou dados de wearables diretamente no celular, garantindo conformidade com HIPAA/GDPR, pois os dados médicos nunca saem do aparelho.
- Enterprise Code Analysis: Um plugin de IDE que usa um SLM local para sugerir refatorações em código proprietário sensível. O código da empresa nunca toca um servidor de terceiros, eliminando o risco de vazamento de IP.
Checklist regulatório rápido: classifique dados (PII, PHI, código sensível), defina política de retenção local e crie trilhas de auditoria para provar conformidade em board meetings.
WebGPU: O Poder da IA no Navegador
Graças ao padrão WebGPU, o navegador se tornou um ambiente de execução de IA de primeira classe. Não precisamos mais de servidores Python complexos; podemos rodar modelos Llama e Phi diretamente no Chrome ou Edge, usando a GPU do usuário.

Veja como é simples inicializar um chat com WebLLM (projeto do MLC AI):
import * as webllm from "@mlc-ai/web-llm";
async function main() {
// Configuração do modelo Llama-3 (versão quantizada para browser)
const selectedModel = "Llama-3-8B-Instruct-q4f32_1-1k";
// 1. Inicializa a engine usando WebGPU
const engine = await webllm.CreateMLEngine(
selectedModel,
{ initProgressCallback: (report) => console.log(report.text) }
);
// 2. Inferência local (Zero latência de rede, Zero custo de servidor)
const reply = await engine.chat.completions.create({
messages: [
{ role: "system", content: "Você é um especialista em Edge AI." },
{ role: "user", content: "Por que WebGPU é importante para LLMs?" },
],
});
console.log(reply.choices[0].message.content);
}
main();Isso não é protótipo. É produção. Estamos entregando experiências de IA ricas para milhões de usuários sem gastar um centavo em GPUs na nuvem.
Quando usar WebGPU vs NPU
- WebGPU: ideal para experiências zero-friction e POCs que precisam rodar no navegador sem instalação.
- NPU: melhor escolha para workloads contínuos, com acesso ao filesystem e telemetria offline.
- Híbrido: use WebGPU como fallback quando o dispositivo não expõe API de NPU.
KPIs e ROI que Tech Leads Monitoram
- Latência percebida pelo usuário final: medir P75/P95 com observabilidade na borda.
- Custo por sessão assistida: comparar rota SLM vs rota LLM premium para provar economia anualizada.
- Taxa de confidencialidade garantida: % de sessões atendidas localmente que permanecem compliant (meta 100%).
- Velocidade de iteração do modelo: tempo entre ajustes do SLM e rollout OTA para a base instalada.
Quando apresento para CFOs, coloco esses quatro KPIs em um dashboard que mostra impacto no OPEX de IA mês a mês.
Checklist para Adotar SLMs na Borda
- Classifique workloads: identifique tarefas que exigem raciocínio pesado vs automações repetitivas.
- Escolha o modelo: Phi-4 para reasoning estruturado, Llama-4 para multimodal, Mistral SLM para chat generalista.
- Defina política de dados: criptografia local, TTL e fallback seguro.
- Implemente roteamento semântico: monitore hit ratio, latência e custo.
- Automatize updates: OTA assinado + telemetria de performance.
Conclusão: Inteligência como Commodity Distribuída
Ser um Arquiteto de IA em 2026 significa entender que a inteligência não está mais centralizada em um data center na Virgínia. Ela é uma commodity distribuída, presente no bolso do seu usuário, no roteador da sua casa e no painel do seu carro.
Enquanto todo mundo discute benchmarks, os líderes que capturam valor sabem combinar SLMs, Edge AI e FinOps. A habilidade de escolher o modelo certo para a tarefa certa — equilibrando precisão, latência, privacidade e custo — é o que separa plataformas enterprise de experimentos de laboratório.
Se quiser trocar ideias sobre como transformar esse blueprint em roadmap na sua empresa, me chama no LinkedIn ou responda esta newsletter. Vamos colocar seus SLMs para trabalhar ainda este trimestre.
Principais Aprendizados
- Eficiência sobre Tamanho: O foco mudou de "parâmetros brutos" para modelos especializados e eficientes (Phi-4, Llama-4).
- Hardware Enablement: NPUs e WebGPU tornaram viável rodar modelos de 3-8B parâmetros em dispositivos de consumo.
- Arquitetura Semântica: Usar SLMs como "roteadores" para LLMs maiores reduz custos drasticamente.
- Privacidade por Design: O processamento local elimina riscos de vazamento de dados sensíveis, crucial para Saúde e Enterprise.
- WebLLM: Bibliotecas modernas permitem inferência robusta diretamente no navegador via WebASSEMBLY e WebGPU.
Fontes
- Microsoft Research - Phi-4 Technical Report
- Meta AI - Llama Series & MoE Architecture
- WebLLM Project & WebGPU
- Qualcomm AI Stack - NPU Utilization
Série: IA em Desenvolvimento 2026
- Post 1: SLMs na Borda - Eficiência e Custo ← Você está aqui
- Post 2: Token Economics - FinOps para IA
- Post 3: GreenOps - Sustentabilidade é Lucro
Newsletter
Receba os artigos mais relevantes da semana, sem quebrar seu ritmo de leitura
Um resumo semanal com os melhores posts sobre IA, engenharia de software e tecnologia, enviado no melhor momento para continuar a conversa depois da leitura.

Escrito por
eltonjose
Engenheiro de software e estrategista de produtos digitais, focado em IA pragmática e em transformar experiências de trabalho remoto em aprendizados aplicáveis. Compartilho frameworks e decisões reais que uso em consultorias e projetos.
- Principais temasEdge AI, SLM
- Formato do conteúdoGuia prático + insights de carreira