
Token Economics: Por que seu Agente de IA Pode Quebrar seu Budget (E Como Evitar)

Sumário
- Token Economics: Por que seu Agente de IA Pode Quebrar seu Budget (E Como Evitar)
- O Perigo do "Loop Infinito" de Raciocínio
- Métricas para configurar circuit breakers
- A Regra de Ouro: Cache Semântico
- O Poder dos AI Gateways (LiteLLM)
- Por que usar um Gateway?
- Métricas que Importam: Custo por Resolução
- Dashboard mínimo para Tech Leads e CFOs
- Checklist FinOps para Agentes Autônomos
- Conclusão: Governança é a Chave
- Principais Aprendizados
- Fontes
Token Economics: Por que seu Agente de IA Pode Quebrar seu Budget (E Como Evitar)
Se você gerencia infraestrutura de software tradicional, está acostumado com custos previsíveis. Um cluster Kubernetes tem um preço por nó/hora. Um banco de dados tem um custo por armazenamento. Mas a IA Generativa introduziu uma nova variável na equação financeira: o custo da complexidade cognitiva.
No post anterior da série exploramos como SLMs na borda derrubam latência e custo. Agora avançamos para a segunda perna da tríade: Token Economics. Edge AI reduz o volume de chamadas premium, mas, mesmo assim, um agente mal governado consegue evaporar seu budget em minutos.
O que você vai aprender aqui:
- Como implementar circuit breakers cognitivos para impedir loops de raciocínio.
- Por que cache semântico e gateways como LiteLLM são a base do FinOps de IA.
- Quais métricas convencerão CFOs e heads de produto a aprovarem projetos de IA.
O Perigo do "Loop Infinito" de Raciocínio
O maior vilão do budget de IA hoje não é o preço do token, mas a autonomia do agente. Um agente mal configurado pode decidir que precisa "refletir" sobre uma resposta 10 vezes antes de enviá-la ao usuário.
Se cada reflexão custa $0,05 e você tem 1.000 usuários simultâneos, seu custo explode exponencialmente. E lembre: cada reflexão costuma chamar um LLM premium porque o time configurou tudo para o modelo "mais inteligente".
Solução Prática: Implemente "Circuit Breakers" Cognitivos. Assim como limitamos requisições de rede, precisamos limitar "passos de pensamento". Nenhum agente deve ter permissão para executar mais de N passos de raciocínio sem uma aprovação humana ou hard-stop. Definir um "Budget de Tokens por Requisição" é tão crítico quanto definir timeouts de API.
Métricas para configurar circuit breakers
- Max Thought Steps: 6-8 passos antes de exigir aprovação.
- Tokens por Resposta: teto por tier de usuário (ex.: 4k tokens para plano gratuito, 12k tokens para enterprise).
- Custo por Sessão: alerte quando ultrapassar $0,75 em uma única interação.

A Regra de Ouro: Cache Semântico
A regra número 1 de FinOps para IA é simples: Nunca pague pela mesma resposta duas vezes.
Sistemas tradicionais usam cache por chave exata (Redis). Mas em IA, "Como reseto minha senha?" e "Esqueci minha senha, me ajude" são semanticamente idênticas, mas strings diferentes. Um cache tradicional falharia.
O Cache Semântico (usando bancos de dados vetoriais como Pinecone ou Qdrant) identifica que a intenção é a mesma e serve a resposta armazenada, custo zero de LLM. Empresas que implementam cache semântico veem redução de 30% a 50% na fatura de inferência no primeiro mês.
Playbook rápido:
- Gere embeddings com o mesmo provedor do LLM (minimiza drift semântico).
- Salve contexto, resposta final e metadados de custo.
- Estabeleça TTL dinâmico: artigos de suporte podem expirar em 30 dias; políticas legais, nunca.
- Monitore cache hit rate semanal e correlacione com redução real em gastos.
O Poder dos AI Gateways (LiteLLM)
Para ter controle total sobre custos, você não pode deixar seu código chamar a OpenAI ou Anthropic diretamente. Você precisa de um intermediário: um AI Gateway.
Ferramentas como o LiteLLM se tornaram o padrão da indústria para gerenciar o tráfego de LLMs. Elas atuam como um proxy reverso inteligente que centraliza todas as chamadas de IA da sua empresa.
Por que usar um Gateway?
- API Unificada: Troque de GPT-4 para Claude-3 ou Llama-3 alterando apenas uma configuração, sem reescrever código.
- Controle de Orçamento: Defina limites de gastos por usuário, por chave de API ou por projeto. "O time de Marketing só pode gastar $50/mês".
- Fallbacks Inteligentes: Se a OpenAI estiver fora do ar (ou se o modelo for muito caro para a tarefa), o gateway roteia automaticamente para o Azure ou para um modelo open-source mais barato.
- Logging Centralizado: Saiba exatamente quem gastou o quê e onde, com dashboards detalhados.
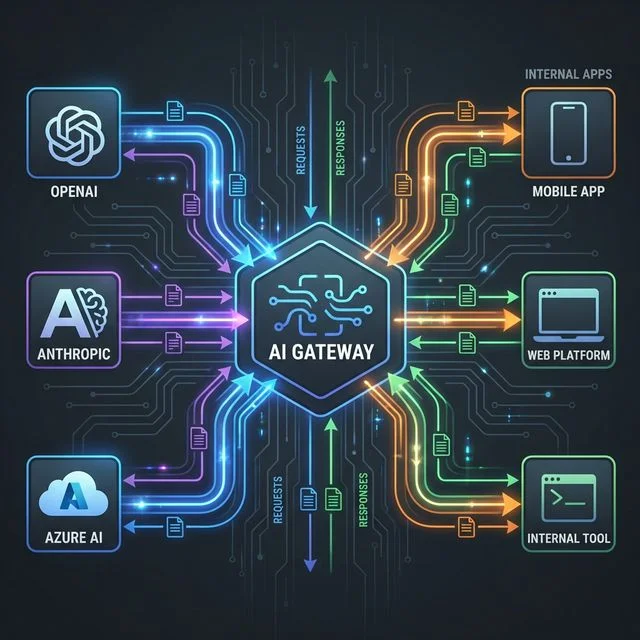
Implementar um gateway é a diferença entre receber uma fatura surpresa de $10.000 e ter previsibilidade total sobre seus custos operacionais. Além disso, você consegue aplicar as mesmas políticas de roteamento semântico que descrevi no post sobre SLMs na borda, só que agora orientadas a custo.
Métricas que Importam: Custo por Resolução
Pare de medir "Custo por Token". Isso é métrica de vaidade para infraestrutura. A métrica de negócio real é Custo por Resolução de Tarefa.
Se um modelo barato (GPT-3.5 ou Llama-3) precisa de 5 tentativas para escrever um código correto, e o GPT-5 acerta na primeira, o modelo "caro" foi, na verdade, mais barato.
FinOps maduro em 2026 significa monitorar a eficácia. Um agente que gasta $1,00 para fechar um ticket de suporte de forma autônoma é infinitamente mais barato que um humano, mesmo que o custo de API pareça alto isoladamente.
Dashboard mínimo para Tech Leads e CFOs
- Custo por Resolução (CPR): total gasto / tickets resolvidos.
- Token Mix: % gasto em SLMs vs LLMs premium (alvo: 70/30).
- Tempo Médio por Resolução: correlacione com satisfação do usuário.
- Porcentagem de Sessões Cacheadas: indicador direto de eficiência do cache semântico.

Essas visualizações ajudam o time executivo a enxergar quickly quais alavancas mexer: se o mix de tokens foge do alvo, você atua no roteamento; se o CPR sobe, revisita prompts ou ativa modelos mais assertivos.
Checklist FinOps para Agentes Autônomos
- Defina limites: passos de pensamento, tokens por sessão, modelos autorizados.
- Implemente cache semântico: monitore hit rate e refreshe conteúdos críticos.
- Centralize chamadas em Gateway: aplique políticas de custo, observabilidade e failover.
- Integre Edge + Cloud: SLMs tratam o volume, LLMs premium resolvem o que agrega valor.
- Reportar semanalmente: CPR, token mix e sessões inválidas (loops, falhas, repetições).
Conclusão: Governança é a Chave
A liberdade radical que demos aos desenvolvedores para "brincar com IA" em 2024 acabou. Agora, precisamos de governança. Tags de custo obrigatórias em cada feature de IA, gateways centralizados como LiteLLM e cache semântico agressivo são o novo normal.
A IA é uma ferramenta poderosa, mas sem um CFO digital (ou pelo menos um bom script de monitoramento), ela pode ser a ferramenta mais cara que sua empresa já comprou.
Se quiser conectar esse playbook de FinOps com a estratégia de SLMs na borda que vimos no post anterior, me chama. Ajudo times a desenhar roteiros que combinam edge inference com governança financeira em menos de 90 dias.
Principais Aprendizados
- Custo Cognitivo: O preço não é apenas sobre tokens, mas sobre quantos passos de raciocínio lógico um agente executa.
- Circuit Breakers: Implemente limites duros de "pensamento" para prevenir que loops autônomos consumam seu orçamento.
- AI Gateways: Use ferramentas como LiteLLM para centralizar chamadas, impor limites de orçamento e gerenciar fallbacks entre provedores.
- Cache Semântico: Use bancos vetoriais para evitar pagar duas vezes pela mesma resposta.
- Custo por Resolução: Meça o custo para resolver o problema do usuário, não apenas o custo por token.
Fontes
- FinOps Foundation - AI & ML Special Interest Group
- LiteLLM Documentation - Cost Tracking
- Pinecone - Semantic Caching Strategies
- OpenAI - Enterprise Cost Management Guide
Série: IA em Desenvolvimento 2026
- Post 1: SLMs na Borda - Eficiência e Custo
- Post 2: Token Economics - FinOps para IA ← Você está aqui
- Post 3: GreenOps - Sustentabilidade é Lucro
Newsletter
Receba os artigos mais relevantes da semana, sem quebrar seu ritmo de leitura
Um resumo semanal com os melhores posts sobre IA, engenharia de software e tecnologia, enviado no melhor momento para continuar a conversa depois da leitura.

Escrito por
eltonjose
Engenheiro de software e estrategista de produtos digitais, focado em IA pragmática e em transformar experiências de trabalho remoto em aprendizados aplicáveis. Compartilho frameworks e decisões reais que uso em consultorias e projetos.
- Principais temasFinOps, Custos de Cloud
- Formato do conteúdoGuia prático + insights de carreira